
Sharing 3 options to find duplicates using SQL in RDBMS

Introduction
- Relation tables may or may not contain duplicates. Depending on the use case it may or may not be required. In case it is not required we often need to find such occurrences and perform the deletion followed by adding unique constraints on the columns.
- In this article, we will learn 3 options to find duplicates in a relational table using SQL.
Sample Table: Accounts
select count(*) from accounts;

Detecting Duplicates
- Before writing SQL logic to find duplicates we need to define the criteria for duplicates.
- For some use cases, it can be a single column that may be duplicated, for some, it may be a combination of some columns, and it’s also possible that the entire row (except the primary key )is duplicated.
Option 0: Using Having Clause With Count
Single Column
- Finding duplicate values for a single column is very easy. We can use the count operation on the column and filter all the columns with values greater than 1.
- For example, if we need to calculate duplicate usernames in the account table, we can use the having clause with the count on the username column.
- Having a Clause in SQL can be used with aggregation like count in the below example.
select username
from accounts
group by username
having count(username) > 1 ;
Multiple Columns
- We can expand the above logic and include multiple columns to find duplicate rows with those multiple columns being duplicated.
- We need to group the query using those multiple columns and check the count using a having clause as we did with a single column.
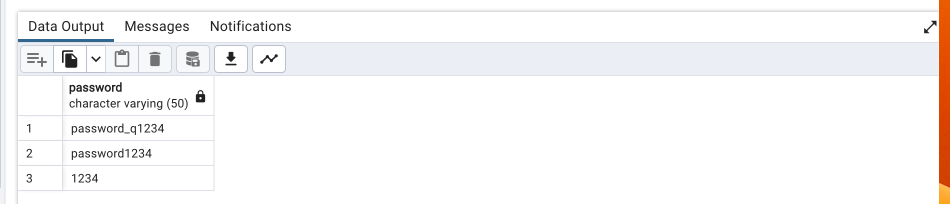
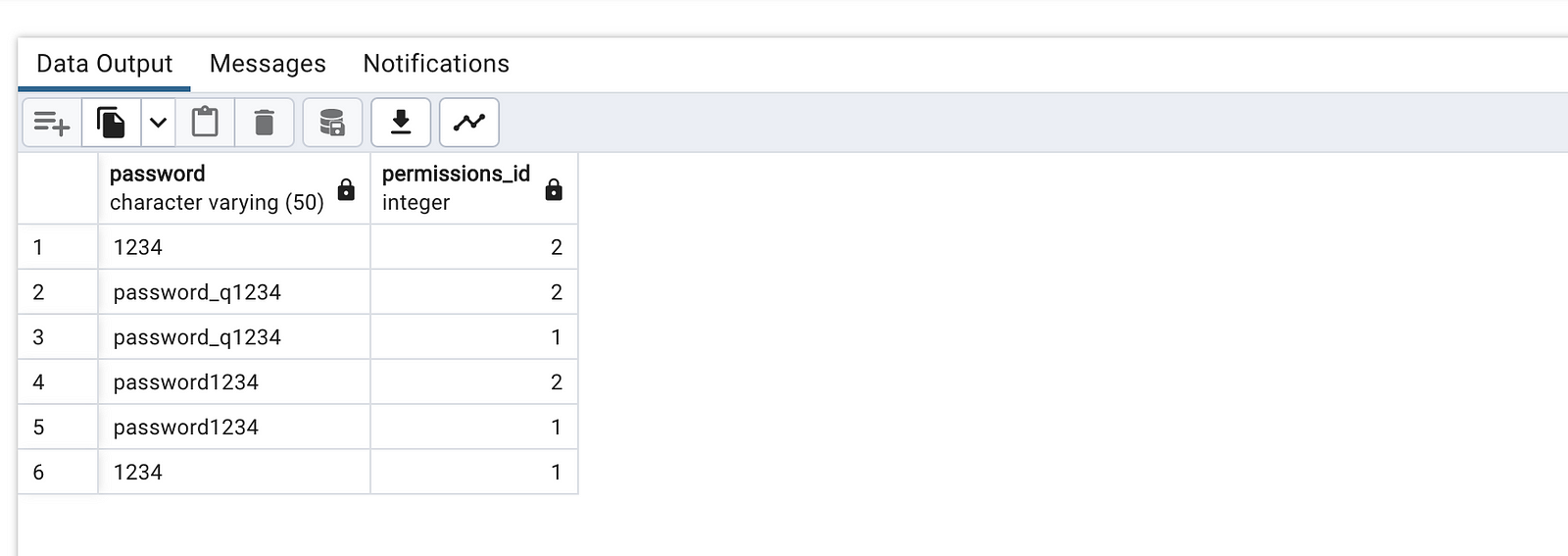
select password, permissions_id
from accounts
group by password, permissions_id
having count(*) > 1 ;
Option 2
- Another approach is writing a subquery that reads the username and counts all the occurrences of that username in the SQL, then using the result as a base query to write a filter query where the occurrence is greater than 1.
select username from (
select username, count(*) as occr
from accounts
group by username
) x where x.occr = 1
Multiple Columns
- Adding multiple columns is simple and it’s just adding more columns to select a query and group by those columns.
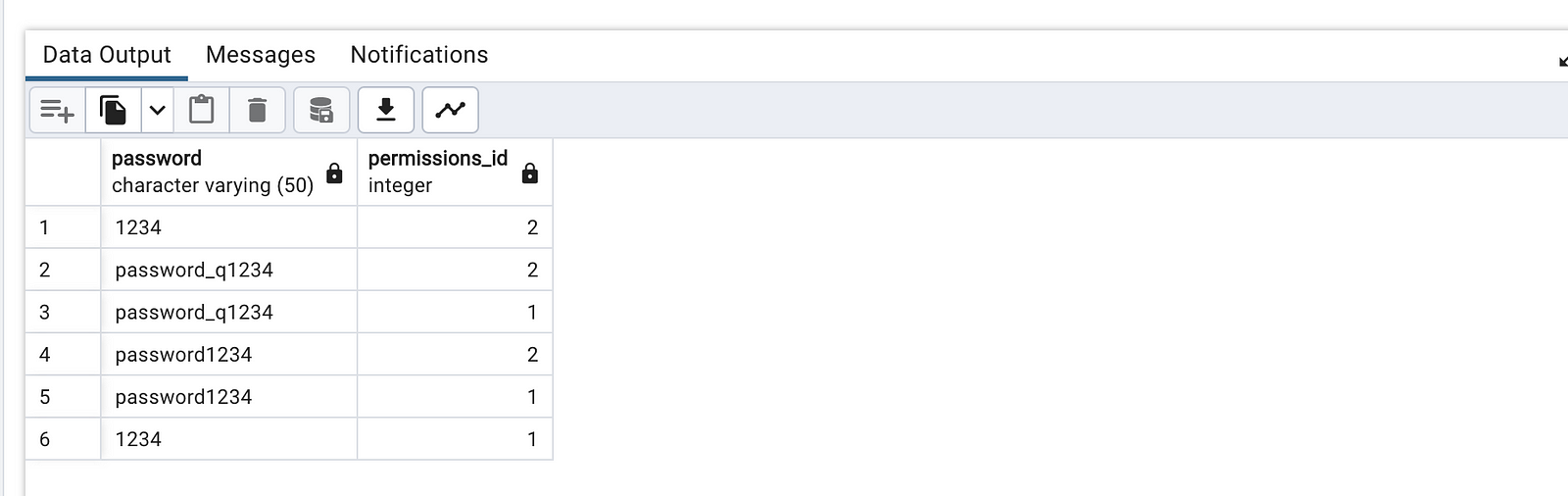
select password, permissions_id from (
select password,permissions_id, count(*) as occr
from accounts
group by password, permissions_id
) x where x.occr > 1
Option 3: Using JOIN
Single Column
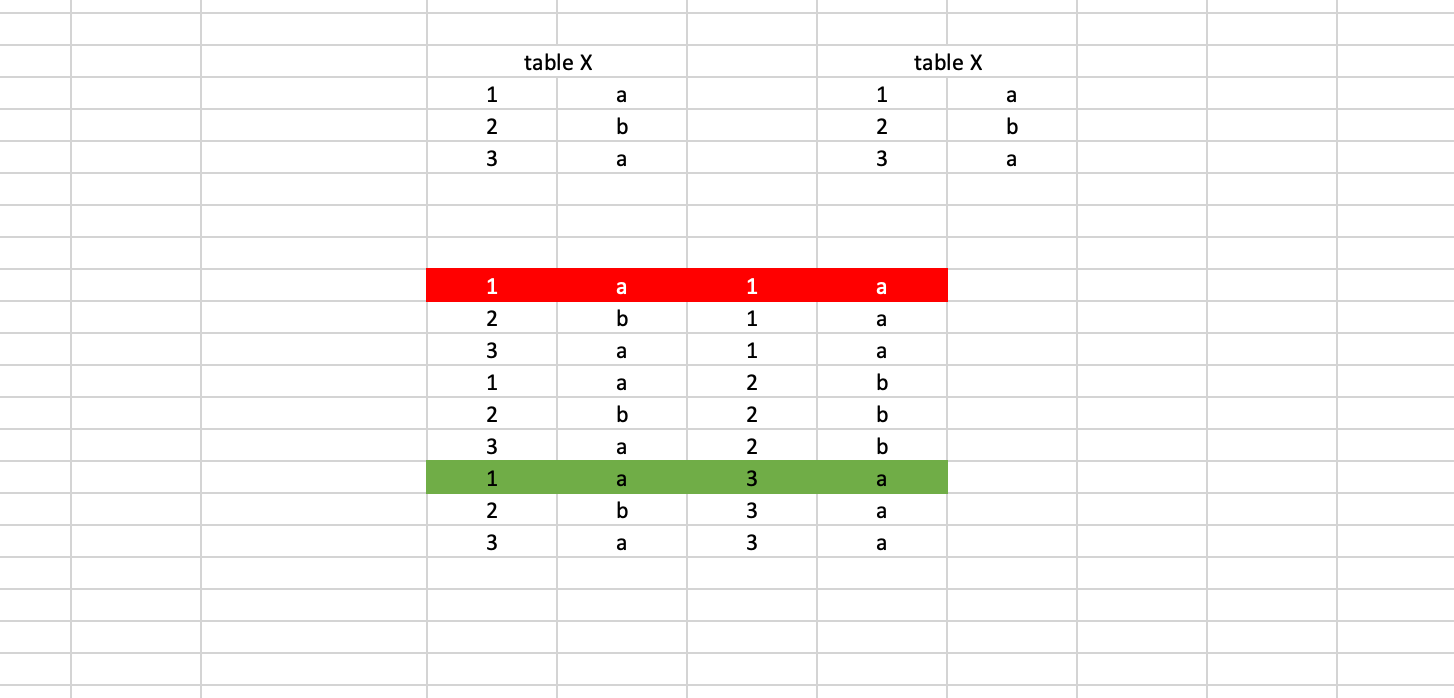
- We can also use INNER JOIN on the self table as shown below. As we can see below we are joining over cases where passwords between two tables are the same but the ids are not the same, otherwise, we will get the same record as counted as duplicated.
- In the below example, when we perform inner join only rows with matching clause conditions will be selected across two tables.
- If we don add the “`a1.user_id <> a2.user_id“` condition then it will select a red cell as well which is not correct since its duplicating the same row.
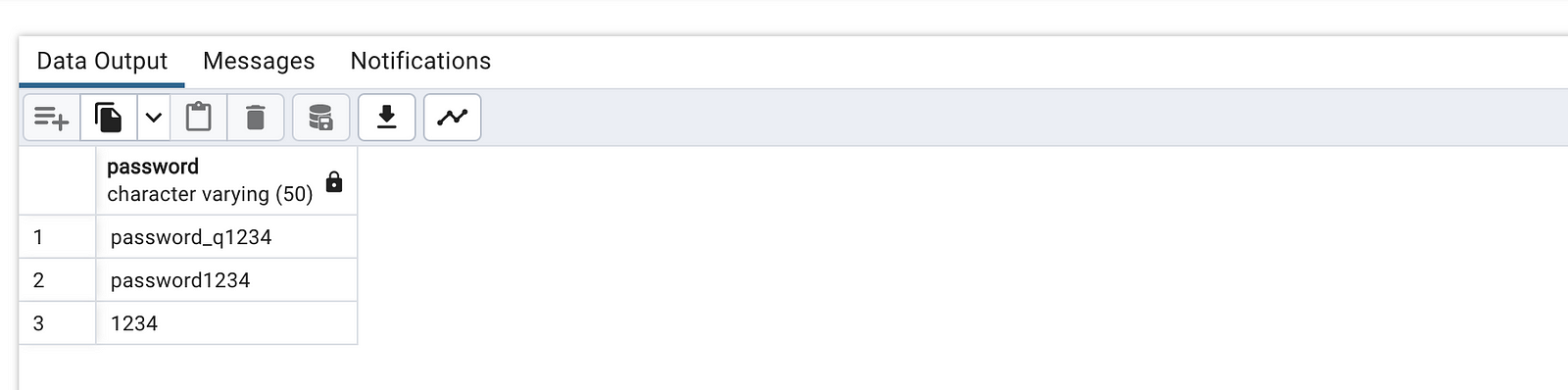
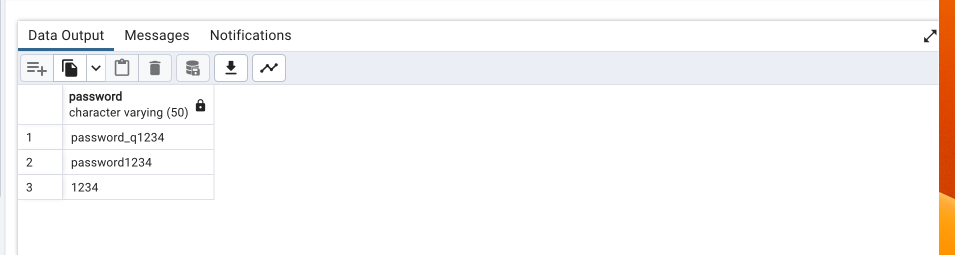
select distinct a1.password
from accounts a1
inner join accounts a2
on a1.password = a2.password and a1.user_id <> a2.user_id;
Multiple Column
- Expanding over single-column logic we can add more columns to select query, but we need to add that column to ON clause.
- Now select query can return multiple rows with the same values except for different user_id, so in order to return unique we can use distinct for those columns, and select will return a distinct combination of columns as a result.
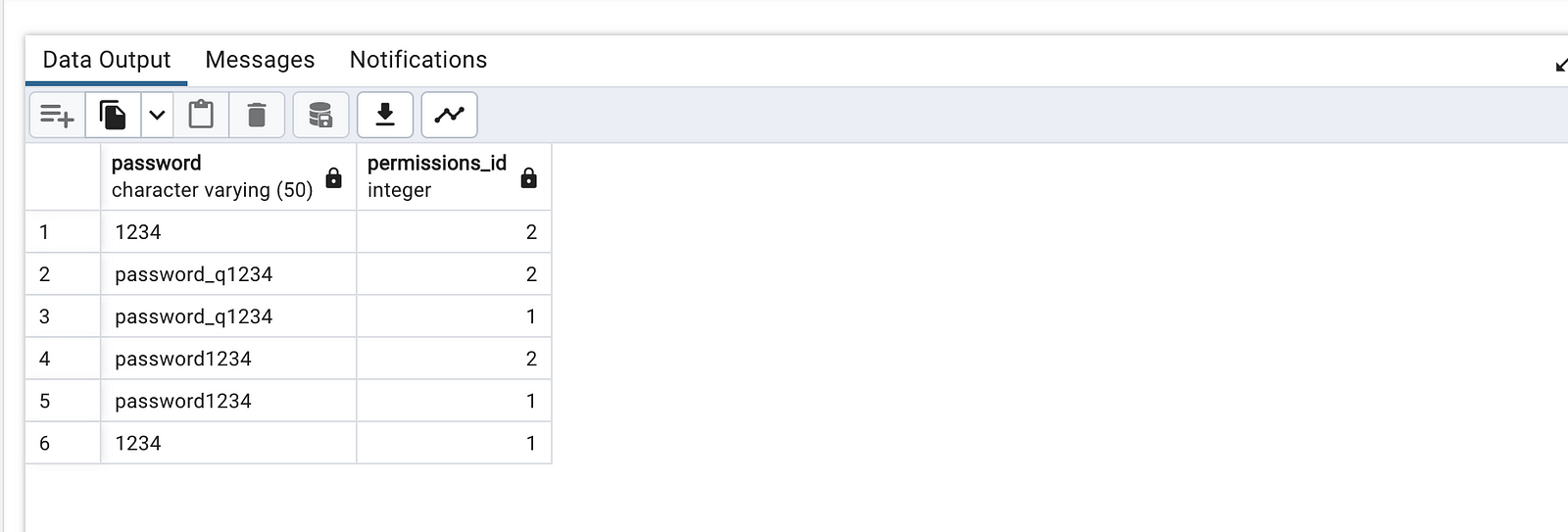
select distinct a1.password, a1.permissions_id
from accounts a1
inner join accounts a2
on a1.password = a2.password and a1.permissions_id = a2.permissions_id
and a1.user_id <> a2.user_id;
Conclusion
- In this article, we discussed 3 options to find duplicates in relation tables using SQL.
Before You Leave
- If you want to upskill your database skills checkout Fundamentals of Database Engineering ( 65k + students already enrolled, 4.7 stars, 25 hrs content )