
Three options to read the large tables in Batches

Introduction
- If database tables are small, there is not much engineering would require in terms of querying the database.
- But often we work with tables that are too large in size and our simple query against the table would not work and break things.
- This is where we need to write queries with little caution so that we don’t impact either the database or application layer.
- In this article we will learn how to query a database table that is large in size and a simple SELECT query would return a result that is large in size and can blow up application memory.
Entity
- The entity is a simple Account table.
@Entity
@Table(name="ACCOUNTS")
public class Account {
@Id @GeneratedValue(strategy= GenerationType.SEQUENCE, generator = "accounts_seq")
@SequenceGenerator(name = "accounts_seq", sequenceName = "accounts_seq", allocationSize = 1)
@Column(name = "user_id")
private int userId;
private String username;
private String password;
private String email;
private Timestamp createdOn;
private Timestamp lastLogin;
@OneToOne
@JoinColumn(name = "permissions_id")
private Permission permission;
// getter & setters
}
AccountRepository
- For this exercise, we don’t need to write any derived query by ourselves, instead, we can use the default derived query provided JPARepository, hence AccountRepository is empty.
public interface AccountRepository extends JpaRepository<Account, Integer> {}
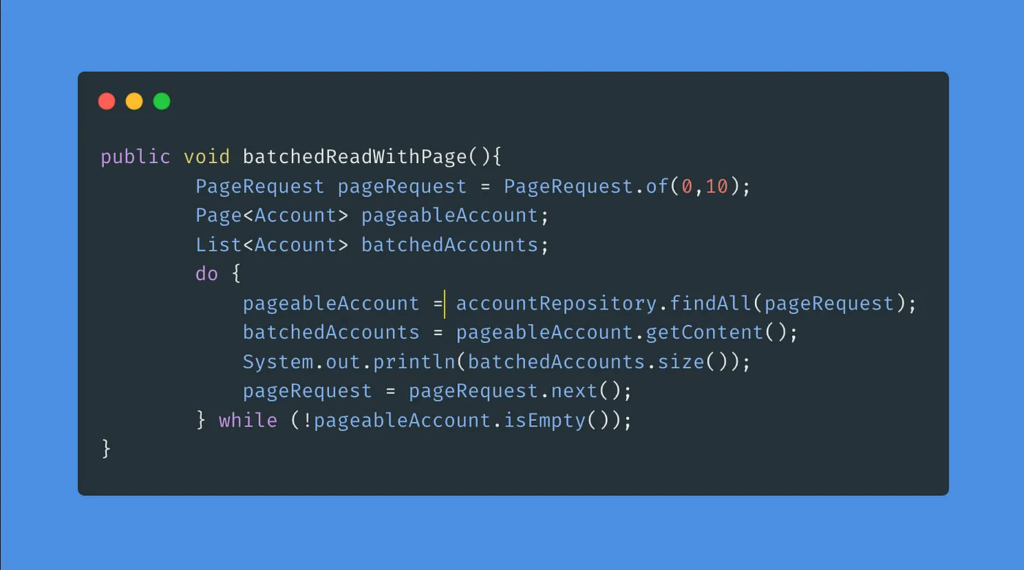
Option 1: Using PageRequest, JPARepository
- This is one of the easy & best approaches to implementing pagination in Spring Data JPA.
- At first, we need to create PageRequest Object
PageRequest pageRequest = PageRequest.of(0,10);
Once we have PageRequest we can pass it to JPARepository as below, the return type is Page.
Page<Account> pageableAccount = accountRepository.findAll(pageRequest);
Now once we have the Page response we can process it and get done with it. Here we are just printing it for brevity.
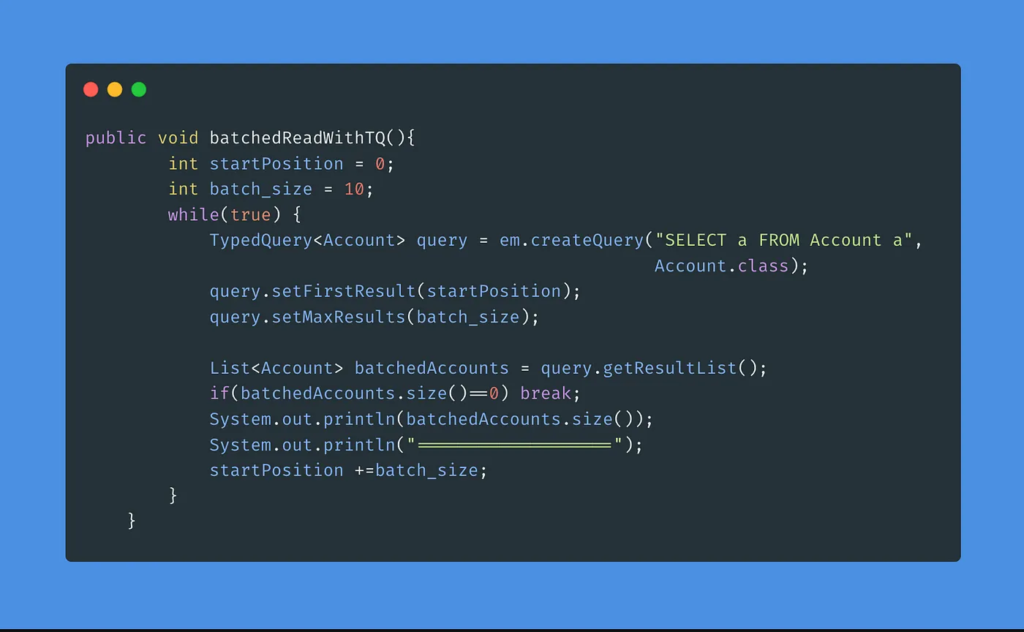
Option 2: Using TypedQuery with StartPosition & MaxResults
- In this example, we will use TypedQuery to query the database. TypedQuery object allows us to set startPosition and maxResult for the response.
TypedQuery<Account> query = em.createQuery("SELECT a FROM Account a", Account.class);
query.setFirstResult(startPosition);
query.setMaxResults(batch_size);
- By using the above setup, it becomes easy to read the record in a paginated fashion.
Option 3: Using PreparedStatement, SQL OFFSET & LIMIT Clause
- We can get a hold of the JPA Session object and Query database bypassing JPA Layer.
- Using RAW SQL we can set OFFSET and LIMIT to return the subset of records instead of reading the entire table.
Session session = em.unwrap(Session.class);
session.doReturningWork(new ReturningWork<>() {
@Override
public Integer execute(Connection connection) throws SQLException {
PreparedStatement preparedStatement = connection
.prepareStatement("SELECT * FROM ACCOUNTS LIMIT ? OFFSET ?");
}
}
Once we have ResultSet that contains results for the given page we can read them like below:
ResultSet resultSet = preparedStatement.executeQuery();
if(!resultSet.next()) break; // break when finish reading
do{
System.out.println(resultSet.getString("user_id"));
}while (resultSet.next());
- The entire logic for batched read would look something like this:

Conclusion
- In this article, we discussed different ways to read large tables in Spring Data JPA.
- Using Spring Data JPA PageRequest is by far the best approach due to its easy-to-use and less mechanical approach.
Before You Leave
- Upgrade your Java skills with Grokking the Java Interview
- If you want to upskill your Java skills, you should definitely check out
[NEW] Master Spring Boot 3 & Spring Framework 6 with Java
[ 38 hrs content, 4.7/5 stars, 6+ students already enrolled]