
Introduction
BigQuery is a data warehouse that is built for the cloud. Its google proprietary data warehouse solution on Google Cloud Platform.
BigQuery is Serverless that means as a customer we don’t have to configure/manage any servers & storage.It will be done behind the scene by google. as a customer, our job is to upload the data and query that means which just focus on business rather than thinking about infrastructure.
BigQuery is not a transactional database like Mysql or Oracle. BigQuery is designed for analytical workloads.
For Example, Query like below is called an analytical query because its purpose is to analyze the data and provide some calculative results like count, max, min, avg, etc.
Here we trying to find titles and total_views for each Wikipedia page.
SELECT title,
count(views) as total_views
FROM
`bigquery-public-data.wikipedia.pageviews_2020`
WHERE
DATE(datehour) = “2020–04–18”
GROUP BY
title
ORDER BY
total_views
DESC;
Analytical queries are very useful in reporting and business intelligence because it provides insights from data based on which Business side can make the tactical decision for the company.
Architecture
Being Serverless we actually don’t need to know about underlying architecture but in knowing it would be helpful for us to optimize our query, cost & performance in some scenarios.
BigQuery is built on top of Google Dremel technology which is used inside google since 2006 in many services in production. (Please refer reference section for the paper)
Dremel is google’s interactive ad-hoc query system which is designed to query read-only data. BigQuery uses Dremel for its execution engine.
Apart from Dremel BigQuery uses Google’s innovative tech like Borg, Colossus File Syste, Jupyter network, and Capacitor.
High-Level Architecture of BigQuery Service
Borg: Borg is the Cluster Management Service of Google to provision compute resources for the Dremel jobs.
CFS(Colossus File System): Underlying storage system.
Jupyter: Googles network
Capacitor: Google’s Columnar Storage format.
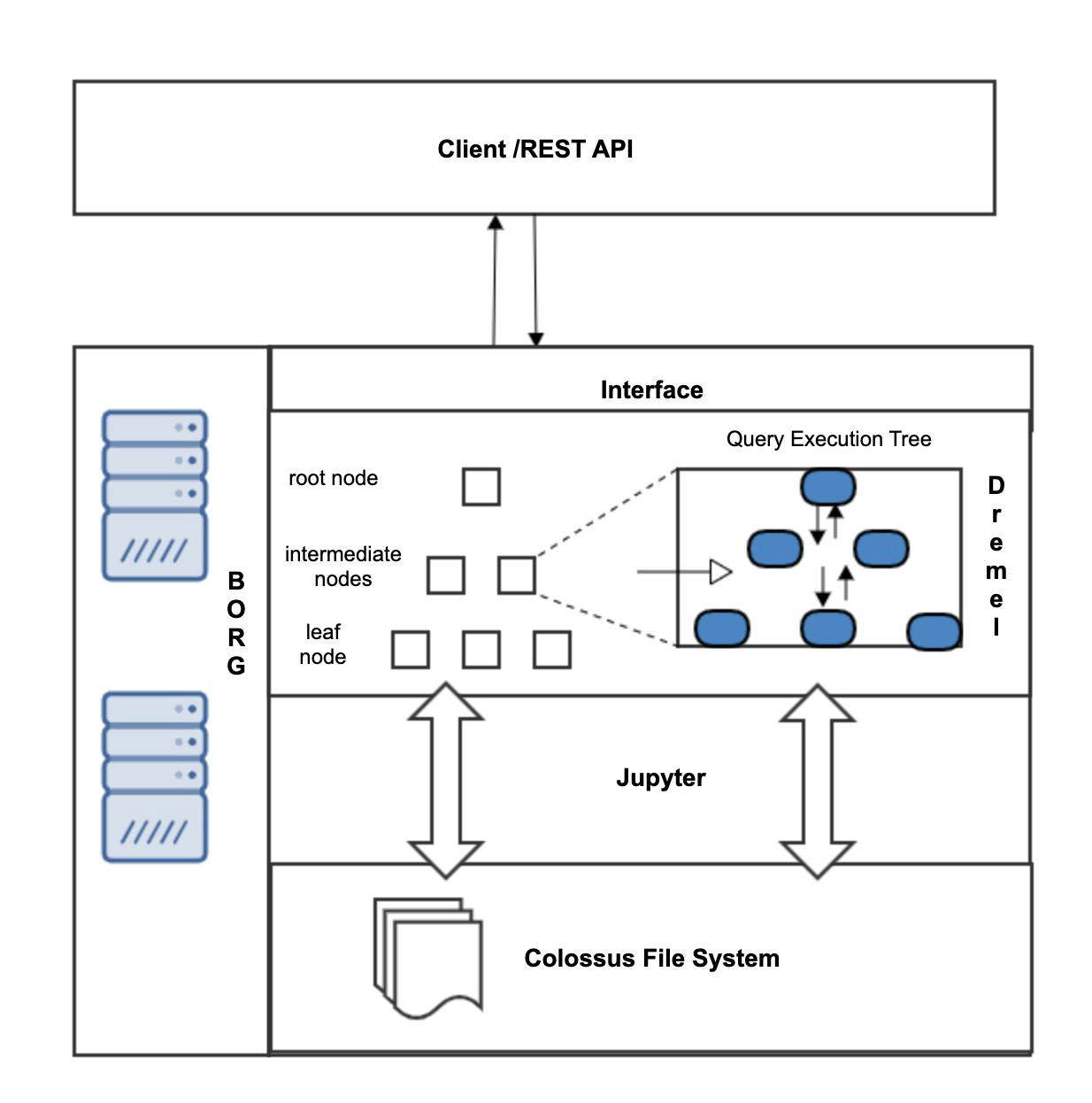
As we can see in the above diagram, when the user executes query via command line or GUI or rest API, its interact with Dremel query engine via an interface . Borg then allocated compute to these Dremel jobs. By using google high-speed network Jupyter each job can read and write data to the Colossus file system. Dremel Jobs executes the query , reads/writes the data on the Colossus file system and returns the results back to the client.
Features
BigQuery has many features and following are some of the important ones:
- Real-time data analytics: BigQuery provides an API to insert data in realtime. This is useful for use cases like fraud detection in the finance & banking domain.
- Machine Learning By SQL: BigQuery ML is one of the flagship features of BigQuery. We can create, train & evaluate our model by SQL itself. Use cases like forecast or classification problem can be achieved just by running SQL.
- SQL interface: Query data into BigQuery is pretty easy if you know standard SQL. We don’t need to write complicated Map-Reduce Job. Simple SQL Query does the Job of data analyzing and returns result within seconds.
- Petabyte Scale: BigQuery is built for big data world hence it promises to analyze petabytes of data in minutes and gigabytes of data in seconds. This is a very big deal in a big data world where we have experienced an hour of long-running queries on gigabytes of data.
- On-demand Pricing: In BigQuery we only pay for what we use. So if we run a query on a gigabyte of data, we pay for storage of data processed and compute used for execution.
- Governance and Security: Access to the data can be controlled with Cloud IAM (Identity and Access Management), so only the authorized personnel will have access to the dataset. Data in BigQuery is encrypted at rest and in-transit.
- Storage and compute separation: This feature is a big deal in the modern data warehouse world. Separation of storage and compute gives the power of scaling compute and storage independently which was very difficult in the traditional data warehouse world.
Competitors
BigQuery operates in cloud data warehouse domain , this domain is has been under improvement for long time .
During on-prem popularity, Teradata got lot of market share and one of the goto product in the market but as cloud is becoming more and more popular and data is growing exponentially , cloud data warehouse will eventually take over on-prem data warehouse solution.
Current popular Data warehouse vendors who operate solely in cloud are :
- SnowFlake
- Redshift
- Azure SQL data warehouse(Azure Synapse Analytics)
In my next Data warehouse Blog I will cover other popular cloud data warehouse which SnowFlake.
I appreciate your time. See you in my next blog. thank you!!