
Introduction
- NoSQL database ( Hence different than Cloud SQL, Cloud Spanner and BigQuery).
- Used for OLAP applications( Like BigQuery) which makes is it different than OLTP databases( Cloud SQL and Cloud Spanner).
- For very large & sparse dataset .
- Very low latencies for both read and write operation(typically in milliseconds).
- Works best with naturally ordered data ( having sequential ordering & only one column can be row key).
- Supports largest data size (petabytes data) with milliseconds of read/write operation. it will perform poorly when data size is below terabyte.
- Need good schema design for optimized performance.
- Somewhat like open source HBase but more powerful (relies on columnar structure)
Advantages of BigTable over open source HBase
- Highly scalable with support of massive data size
- Fully managed and easy to increase nodes
- Simple administrator
- redistributed data across node by looking at usage pattern of users. ( avoid hotspot)
- But need to focus on schema design.
Storage Model in BigTable
- BigTable has 4-dimensional data model like HBase and unlike Cloud SQL or BigQuery which has 2-Dimensional data model.
- Row Key: uniquely identifies as a row, sorted in ascending order, represented internally as a byte string
- Column Family : Logically grouped columns, retrieve data from same column family is efficient
- Column: units in the column family, can be added on the fly,
- Timestamp: used as version number for value stored in a column, mutation happens whenever data changes , it takes extra space in BigTable until BigTable performs compaction and remove unnecessary data.
BigTable Architecture
- Client request is served by front-end server pool which route the read/write request to the BigTable cluster evenly which in turns read/write the data to tablet which is blocks of contagious row.
- Nodes are instance which belongs to the BigTable cluster and handle subset of the request. If one node is doing heavy task thats called hotspotting.
- More nodes can be added to increase the traffic load.
- Tablet are stored in Colossus (google file system) in SSTable format, which is persistent. BigTable nodes doesn’t store any data , instead they only have pointers to each tablet that are stored on colossus.
- Apart from SSTables , writes are also written to shared log to increase durability.
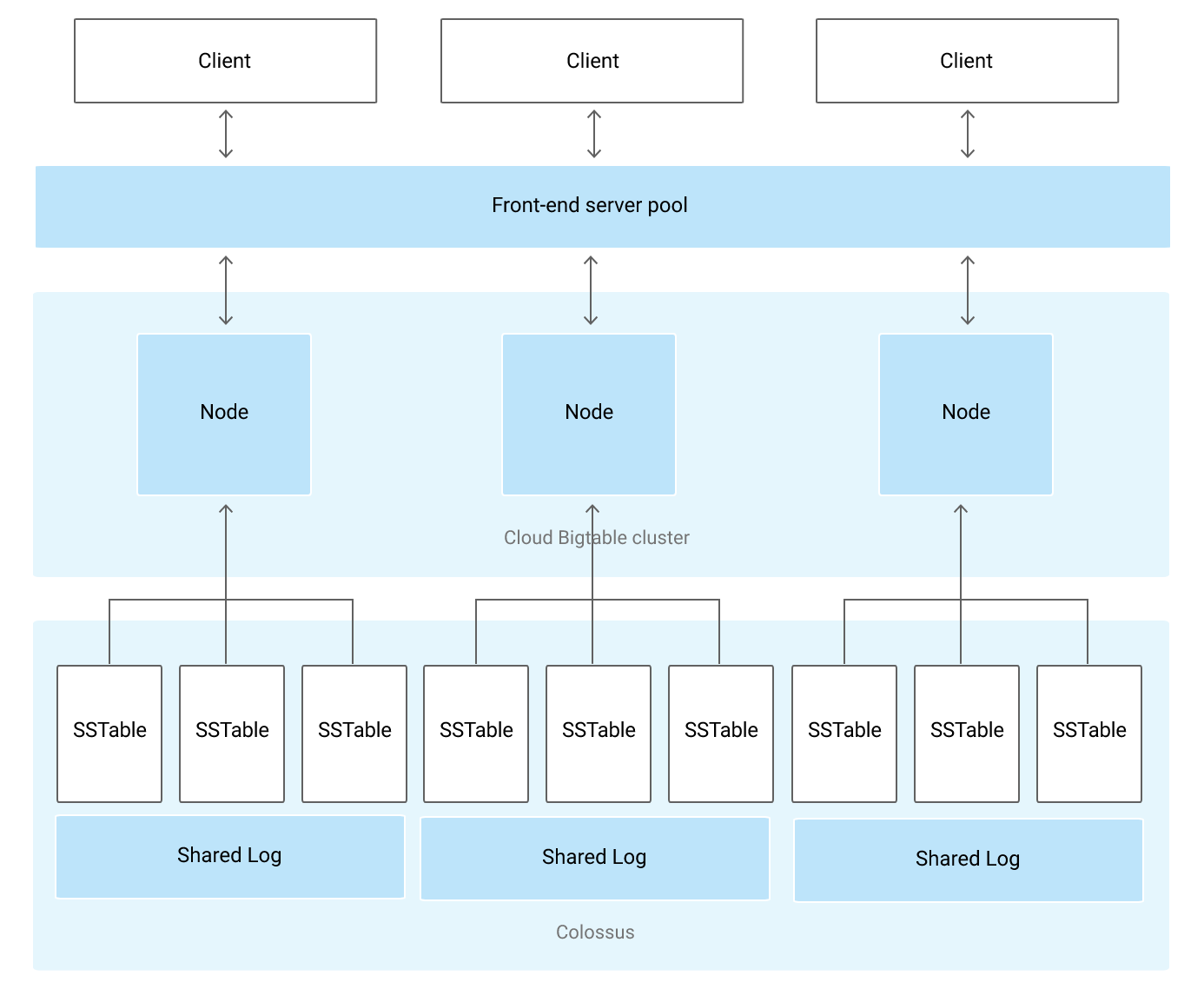
In case of HBase , distributed file system is often HDFS, and Colossus which is distributed files system in BigTable is far better than HDFS in terms of backup, durability.
How to achieve Replication in BigTable ?
- Increase the availability and durability of your data by copying it across multiple regions or multiple zones within the same region.
- We can create instance with more than one cluster , and Cloud Bigtable immediately try to synchronize the data between the cluster by creating independent copy of the data in each zone.
- BigTable support max 4 cluster per zone.
Schema Design
- Row Key : only one index, no sec indices. row sorted by row key.
- work well for sparse data because data with empty values will not extra space in BigTable
- Avoid hotspotting , if certain subset of data accessed together it will cause hotspotting. try to avoid by designing key such a way that request is evenly distributed.
- Also store relative information in same column family, it will speed of data retrieve operation.
- Always check usage pattern with Key Visualizer tool provided by google to find the bottleneck.
How to Connect to BigTable
- CBT tool
- Apache HBase shell
- Programming language supported
BigTable Queries Examples
- Google provides its own command line tool called cbt (written in golang) to work with BigTable. In open source HBase we use HBase shell.
- With cbt you can connect to bigtable, do admin tasks, write data , read data from table
- Create table in BigTable
$ cbt createtable employee- List all the tables
$ cbt ls- Create column family in BigTable
$ cbt createfamily employee basic_info- List column families of the Table
$ cbt ls employee- Put the value in the row with column family
$ cbt set employee $rowkey basic_info:fname=same- Read the data added to the table
$ cbt read employee- Delete the table
$ cbt deletetable my-table
Data Export & Import
- We can export data from Cloud BigTable or HBase as sequence files or binary file.
- If we are migrating on-prem HBase database to Cloud BigTable , then we should first export cloud bigtable as sequence files and then running dataflow job we can import that sequence files into Cloud BigTable.
Working with BigTable using Client Libraries
- BigTable support Java, Python, C#, C++, Node.js, Ruby, PHP client libraries.
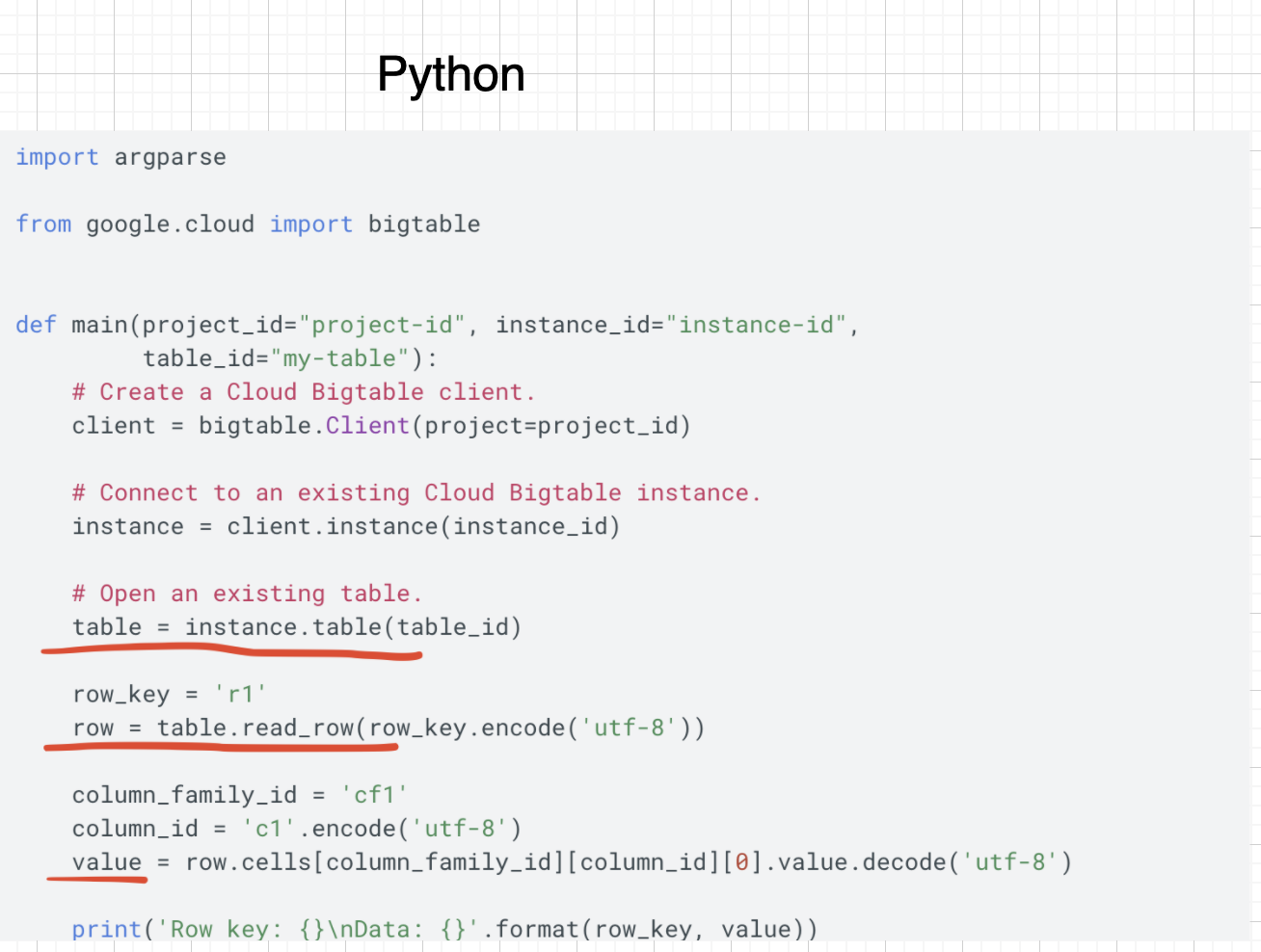
- Example with Python client reading data from BigTable
Use Cases
- Time series data
- Internet of things data
- Financial data (txn data)
- use for > 1TB
When not to use BigTable
- If you need SQL interface
- If you need Data storage for OLTP applications
- If you need Data storage for Unstructured data like image
- If you need Data Storage for hierarchal data like XML docs
That’s all for this blog. See you in the next one!