
Introduction
Google BigQuery provides storage & compute for all sizes of data.
For storing input data it stores it in columnar format which is called “capacitor” and stored in the “colossus” file system.
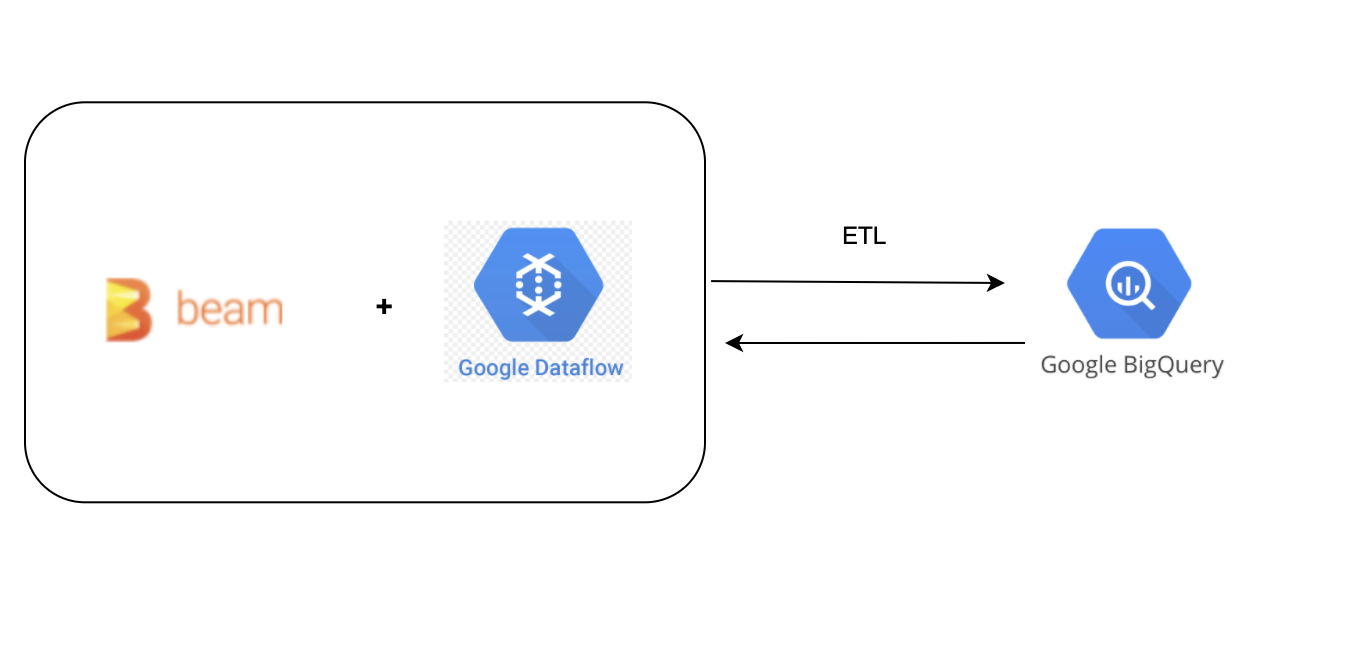
We can execute a data transformation query inside BigQuery and BigQuery will execute our query within seconds. But for some use cases, it makes sense to perform data transformation outside BigQuery using BigData tools such as Spark or Apache Beam which provides compute to the data stored inside BigQuery.
In this blog, we will see how can we perform data transformation outside BigQuery using Apache Beam SDK and Dataflow as an execution engine.
Use Case
Input Table
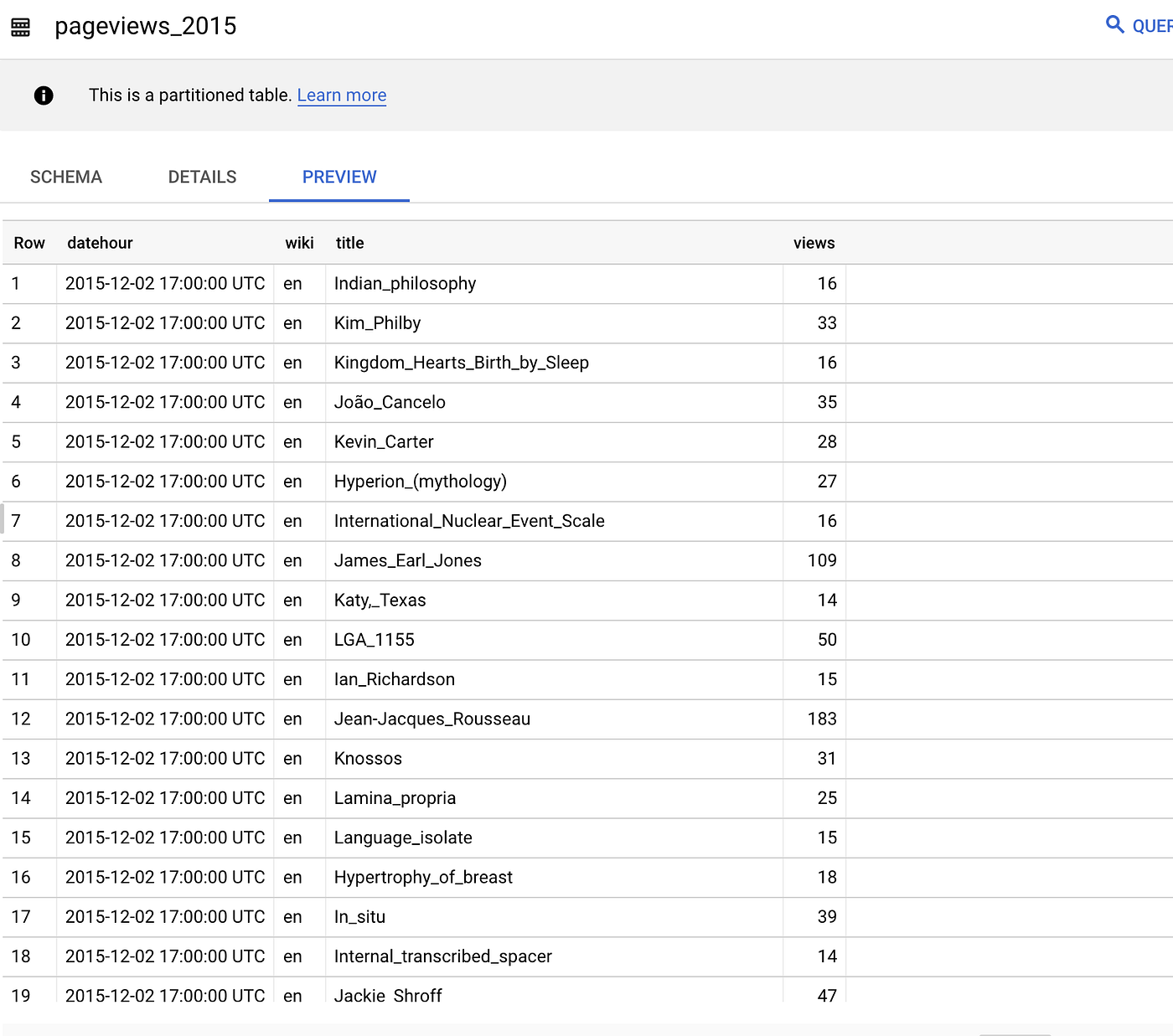
Data Transformation Query

What are our options?
Option 1: We can perform ETL i.e Extract From BigQuery, Transform Inside Dataflow, and Load the result again in the BigQuery destination Table.
Option 2: We can just execute data transformation Query inside BigQuery through dataflow and get the result and Load the result inside BigQuery Table.
Let’s see both options in action.
Option 1:
Extract
Let’s load the entire input BigQuery table in the dataflow.
Below code extract the Wikipedia dataset from BigQuery and Maps the input tabular record to Java POJO Wikipedia Object
Transform
- Since we have input data loaded into Dataflow from BigQuery, We can perform required transformations on the input data using Apache Beam transformations.
- In the below code, we are using inputRecords that we read from BigQuery and apply a transformation that converts PCollection<inputRecords> to KV of Key and corresponding WikiPedia object. We want to group our result by two column hence we create our Key as KV pair, this KV pair will store “wiki” and “title” column and form key for our result.
- Once we created KV pair of key and record, now we can perform count operation by key. this will provide us KV of key and count for that key.
- Now since we performed our transformation, we can map the record to TableRow so that we can append our results to the BigQuery destination table.
Load
- In the transform step, we transformed input records and converted them into TableRow, now we can write load logic to append our result to BigQuery.
- We need to provide a schema of our destination table.
Option 2:
In option 2 we perform extract and transform inside BigQuery since BigQuery provides compute and storage both. and after transformed data is finally appended to the destination table.
Extract and Transform
- We are executing data extraction and transformation query using apache beam. Apache beam allows to executes SQL query on BigQuery datasets.
- Our SQL query perform group by using wiki and title column and perform count operation.
- Don’t forget that this query executes inside BigQuery and Dataflow doesn’t perform any transformations.
Load
- Since our data is transformed, now the only job is left to append to the destination BigQuery table.
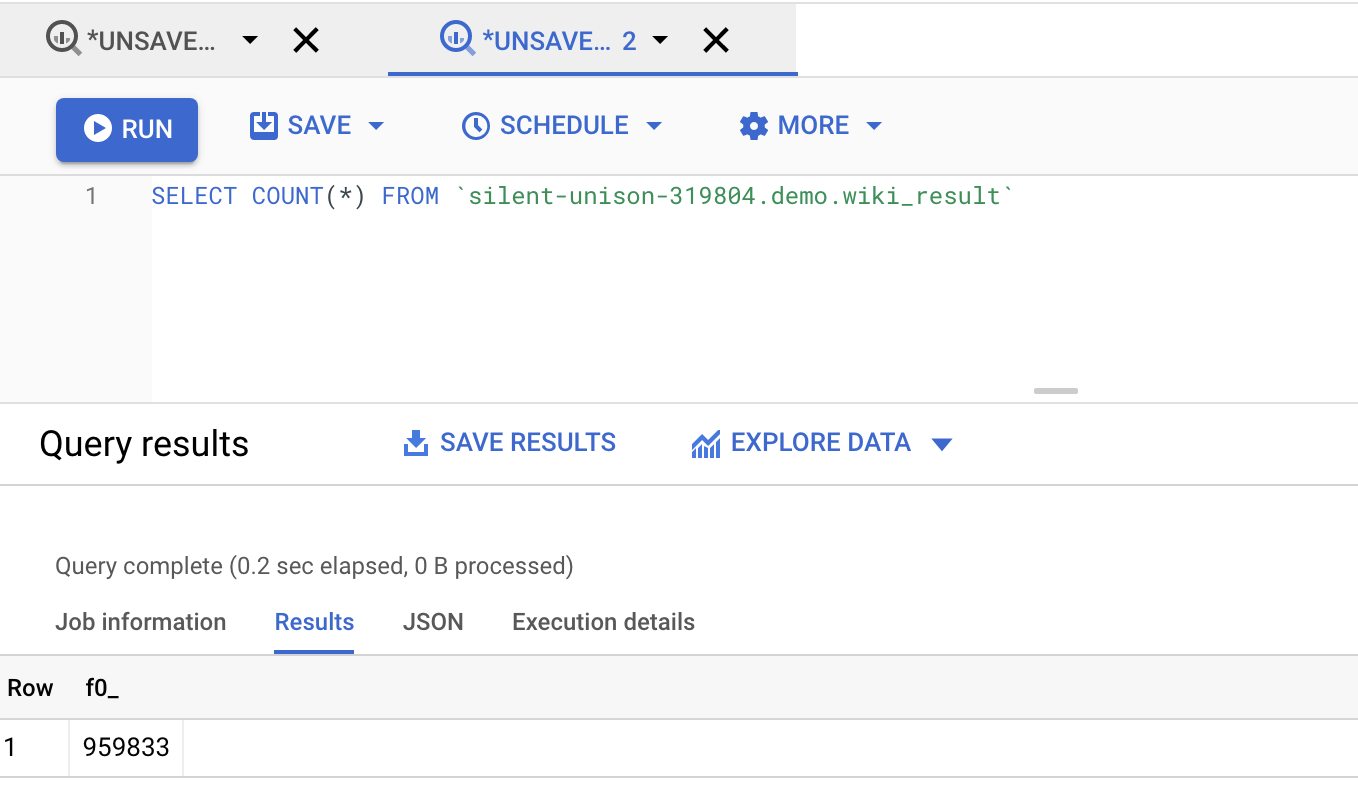
Confirm Record Count
Let’s confirm the count for the records that were appended by dataflow in the BigQuery destination table. Let’s first run the count query.
Now run the transformation using BigQuery and confirm the count on the result.
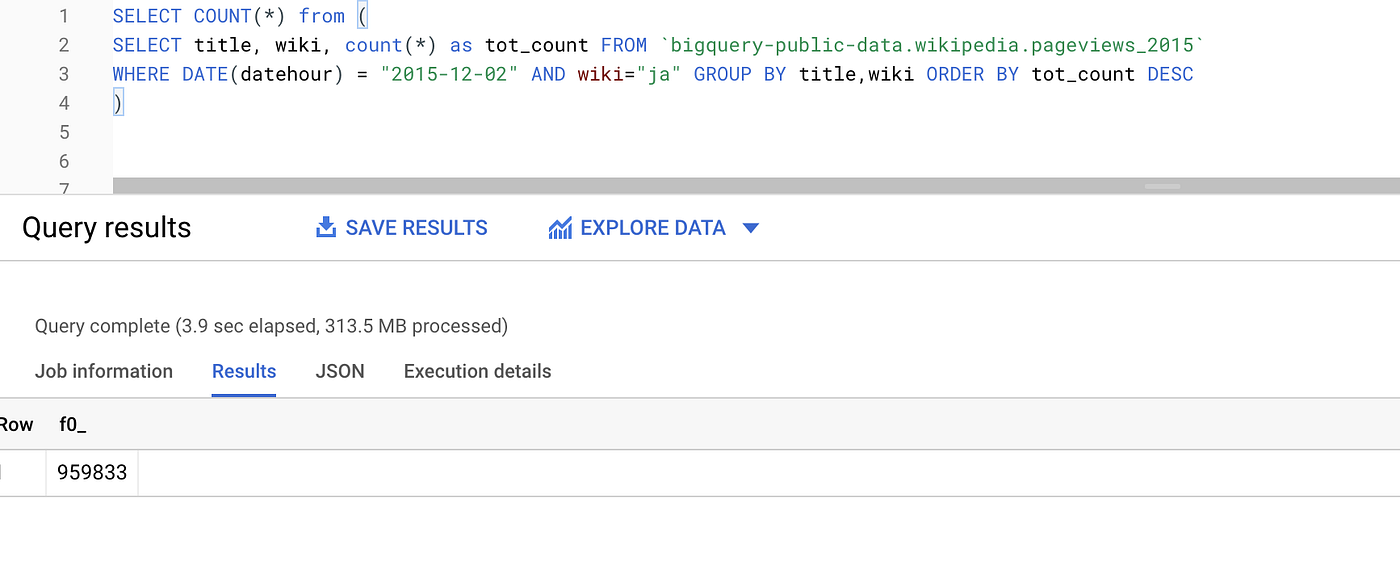
- we can confirm that the record count for ETL with dataflow with transformation done in dataflow is the same as executing transformation query on BigQuery.
Conclusion
- Using Apache beam SDK we can perform ETL either using Dataflow worker machine or Inside BigQuery. Basically, we can either do the transformation on the dataflow worker machine(Option 1) or executing in BigQuery itself(Option 2).
- If we execute transform in BigQuery then dataflow’s job is to just run the execution query on BigQuery which transforms the input data, gets the result, and writes it back to the destination table(source).
but before deciding which option is good you should always do a performance due to diligence and what makes sense for the use case ( executing the transform in BigQuery or Outside BigQuery in data processing engine such as dataflow, Spark, etc. )
