
Introduction to cloud spanner
- Google Cloud Spanner is relational database management system like Cloud SQL on GCP. But it is different than traditional relational databases
What makes it different than Cloud SQL on GCP or Azure SQL or Amazon RDS ?
- It is globally distributed, whereas Cloud SQL is regional.
- It can scale horizontally , that means it can add more nodes to the cluster as data grows. Hence it can support any data size, while Cloud SQL has limitation of 10 TB.
- It offers strong consistency despite of being distributed globally, this is cutting edge built on googles proprietary technologies.
- Its is much expensive than Cloud SQL , hence should be used when data size requirement is more than 10 TB.
Cloud Spanner is revolutionary
- Generally strong consistency can be achieved in vertically scalable databases ( ex Oracle, MySql, PostgreSql) but Horizontally scalable databases(Hbase, Cassandra etc.) are eventually consistent. Hence if we need strong ACID support we will use database like Oracle, MySql & i.e OLTP use cases. But if strong ACID support not required then we will use analytical database such as BigQuery, Snowflake , Redshift, HBase etc i.e OLAP use cases.
- In Short Strong ACID Support -> OLTP Databases
- No Strong ACID Support -> OLAP Databases
- But Cloud spanner provide strong ACID support and its also horizontally scalable , that is indeed differentiator from the product out there in the market.
Configuring Cloud Spanner Instances Options
Cloud Spanner instance can be of type regional or multi-regional.
Regional Instance
- Availability of 99.99 (4 nines)
- Lower Write Latency
- Less Expensive
Multi-Regional Instance
- Availability of 99.999(5 nines)
- Lower Read Latency
- More Expensive
⭐ ️ Each node in Cloud Spanner cluster provides 10k QPS of read and 2k QPS of. writes with 2 TiB of storage.
How Schema & Data Model Looks Like ?
- Unlike relation database tables where we established relation using foreign key, in Spanner we only need to define primary key and need to define parent child relationship if any.
- Spanner will create “split” based on primary key and replicate across the nodes in the cluster.
- Parent table split and child table split will physically stored in the same location based on primary key , hence provides faster data retrieval.
- We need to design keys carefully so that request distributed across nodes and avoids hotspot.
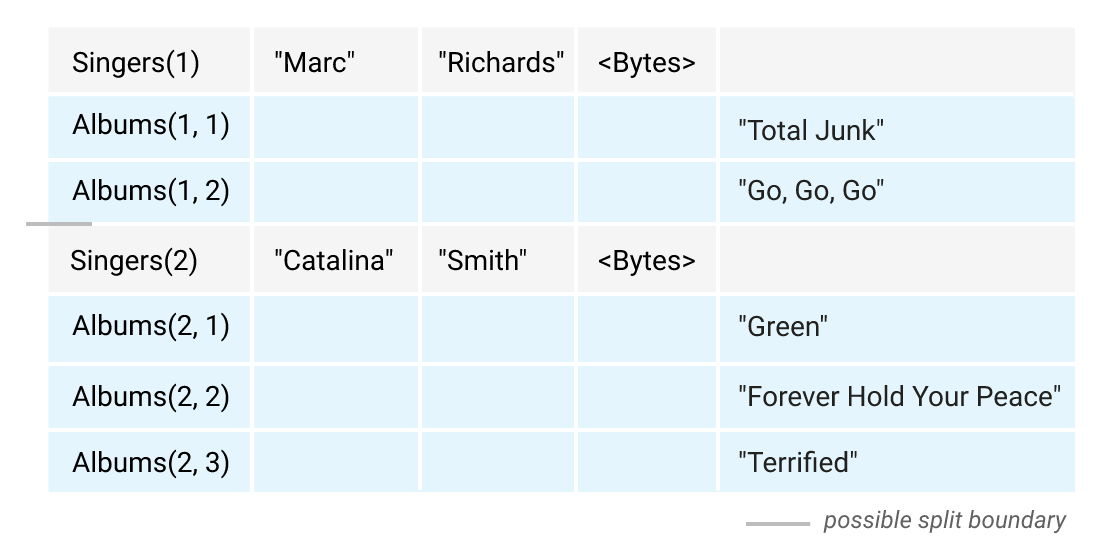
Example , in the below DDL , Album table has primary key which is made up of SingerId as prefix and AlbumId & Its Interleave (Child table) of Parent Singer
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
As you can see singer with id 1 and its interleaved table album having primary key prefix as SingerId physically stored together in order to fast data retrieval.
How Replication Works In Cloud Spanner?
- Spanner Built on colossus files system ( Successor of Google File System) which is googles proprietary distributed file system.
- Colossus internally does replication for each file.
- In addition spanner also adds replication of splits.
- Splits replication synchronization done via paxos algorithm (standard consensus algorithm)
Replicas
- Read-Write replicas : Read-Write replica contain full copy of the split data and can participate in leader election . They can vote on committing write. They can also server read operation. In single region instance , read-write replicas are only allowed.
- Read-only replicas : Only allowed in multi-regional instances. They stored full copy of split data . Replicated from read-write replicas. Cannot vote on commits. only serve to reads operation to avoid latency. They can serve two types of reads. stale read(without round-trip to the leader) and strong read(with round-trip to the leader).
- Witness replicas: Use only in multi-regional instances. Do not maintain full copy of split data. they can vote to commit writes. they can vote in leadership election.they cannot become leader.
For Multi-Regional Instance ,
- We will have 2 read-write regions, 1 witness region
- Each read-write region will have 2 read-write replicas.
- witness region will have 1 witness replica.
- Hence minimum it will have 2*2+1 = 5 replicas
For Regional Instance ,
- We will have minimum 3 read-write replicas , each in different zone for higher availability.
Follow Some Best Practices
- Primary Key : Uniquely identifies each row in the table , determines order of physical storage and colocation. this key can be single column or composite column.
- Secondary Index: An index on non-key column, requires additional space.
- Storing Clause: Store an additional copy of column in index to quickly lookup that column by index.
- Design keys carefully so that request distributed across nodes and avoids hotspot. In traditional database auto-increment keys or increasing values are good design pattern for primary key but they are anti-pattern for cloud spanner.
If you want to learn about other storage options like cloud spanner please read this blog : Exploring Various Storage Options On GCP
Thanks for reading this blog. See you in the next.