
Building Client
- Client for Pubsub can be any data producer like mobile app events, user behavior touchpoints, database changes (change data capture), sensor data, etc.
- Cloud PubSub provides many client libraries such as Java, C#, C++, Go, Python, Ruby, PHP & REST API.
- One can easily integrate client code into data producer to publish the data into Cloud PubSub
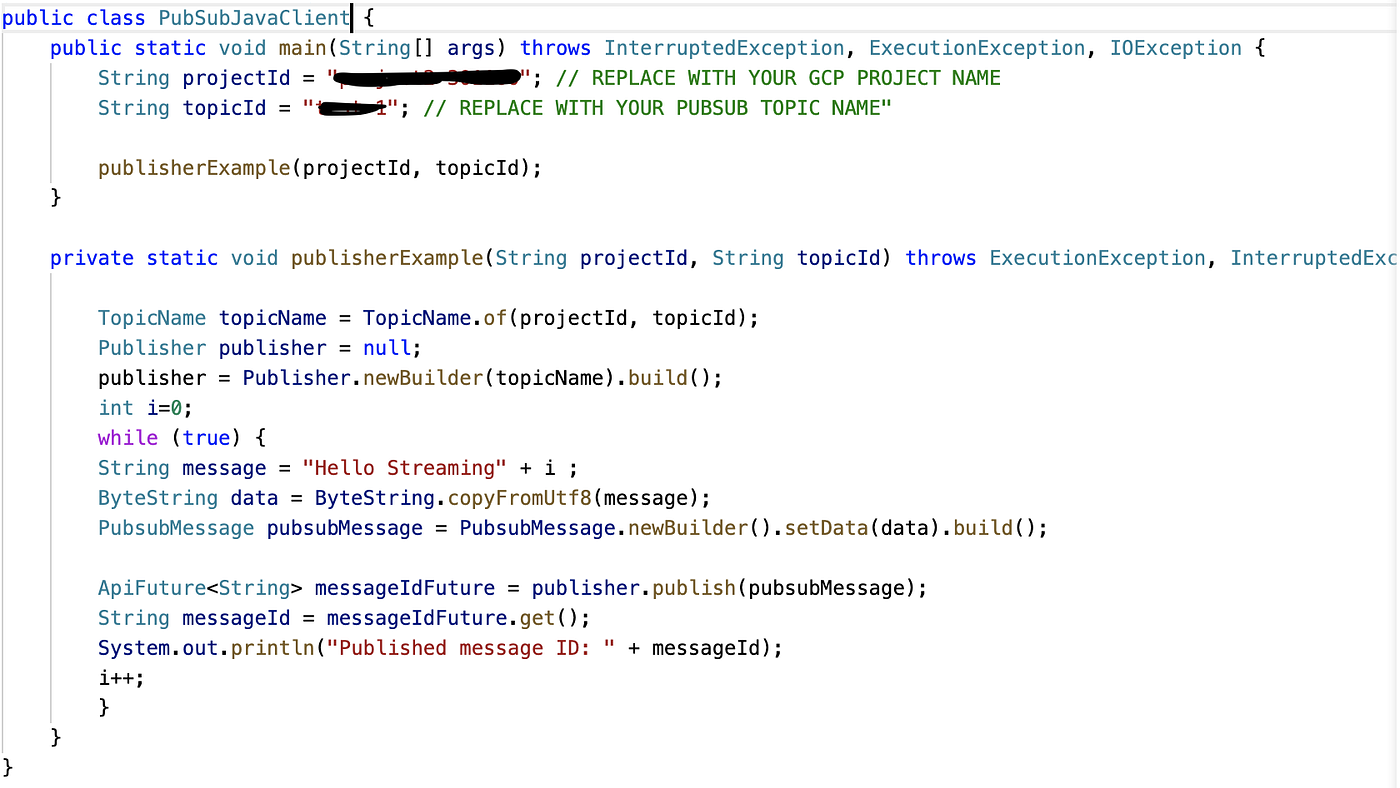
Here is the example of Java Client Code
- This client code is mimicking streaming events using forever while loop.These events are then coverted into byte string .
- PubSub Message is created and initialized with the event that we need to publish.
- Finally event is is published to specified PubSub Topic.
- After publishing event we logged out published message id assigned and returned by cloud pubsub.
- Now goto your pubsub client root project and execute maven to run the client.
/* export service account prior to run below command to provide access to various services
export GOOGLE_APPLICATIONS_CREDENTIALS=~/service_account.json
*/
$ mvn compile exec:java -Dexec.mainClass="PubSubJavaClient"
- After runnig maven execution command you can check following logs about published message_id

- Now lets check if message indeed published to cloud pubsub in step 2
Data Ingestion
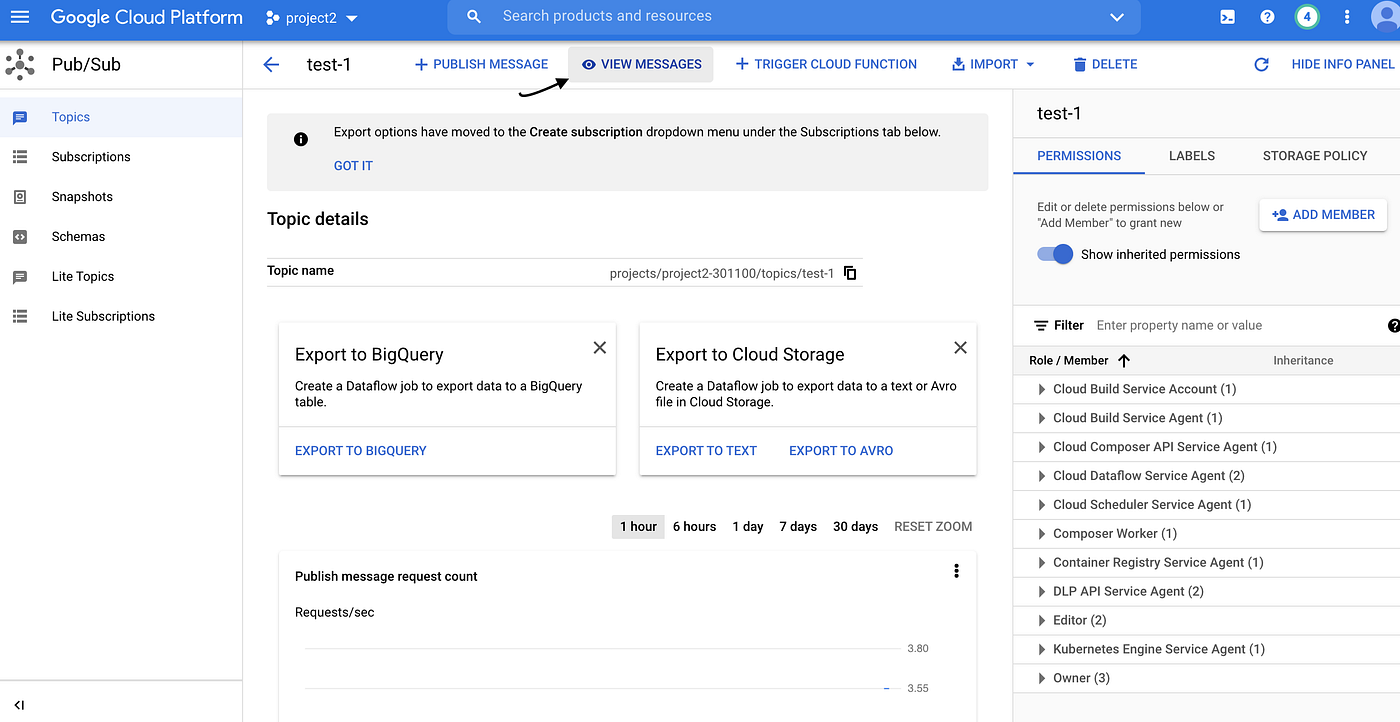
- Let navigate to Cloud Pubsub by clicking hamburger menu on the left side of cloud console
- Goto Cloud Pubsub and click on view message as shown below
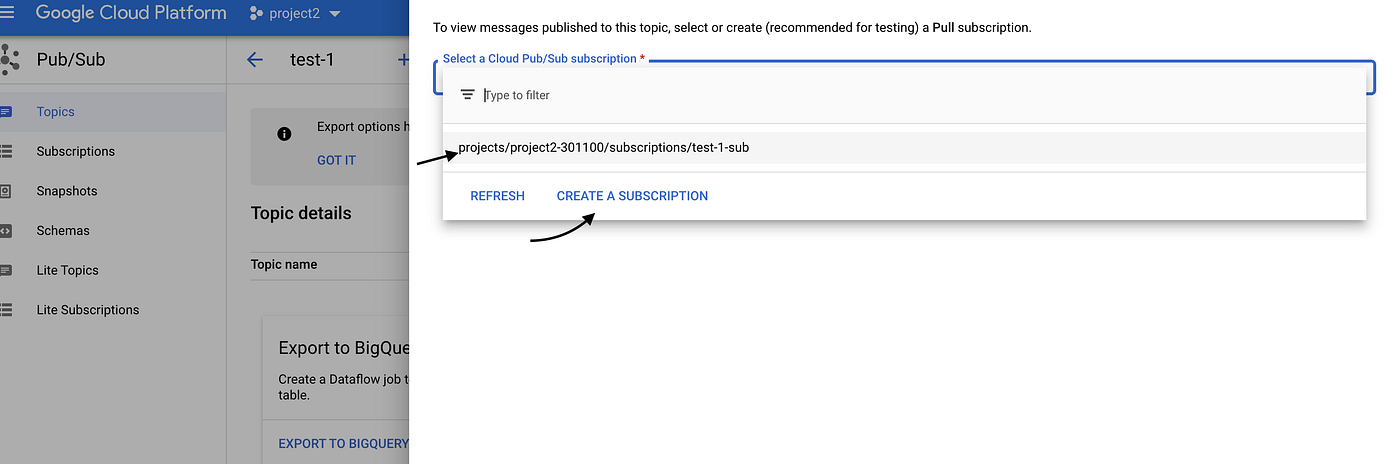
- Popup will be open to choose for subscription, please select subscription if you already have or create one for the topic.
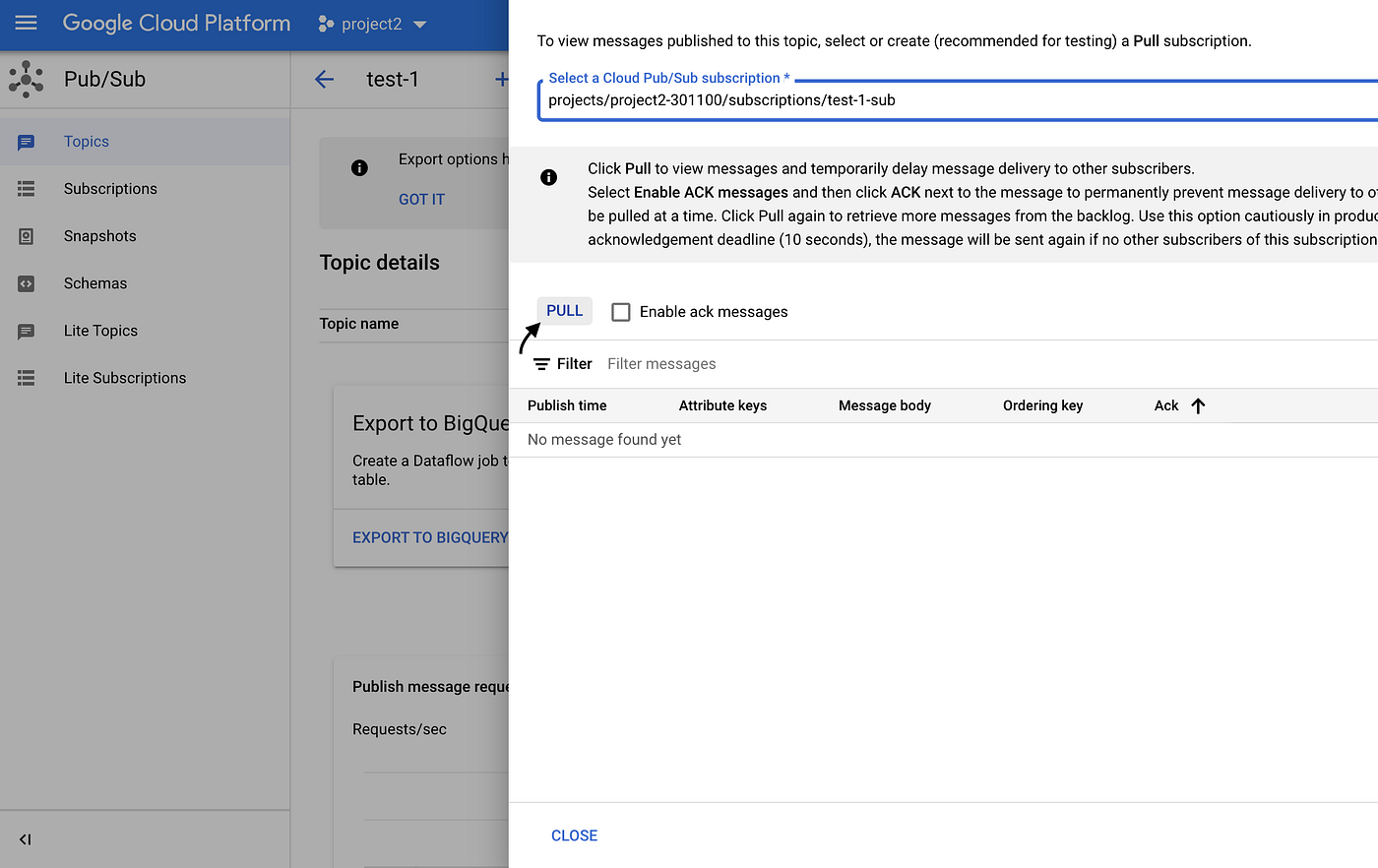
- Click pull message and you should be able to see the message that were published in Cloud Pubsub topic
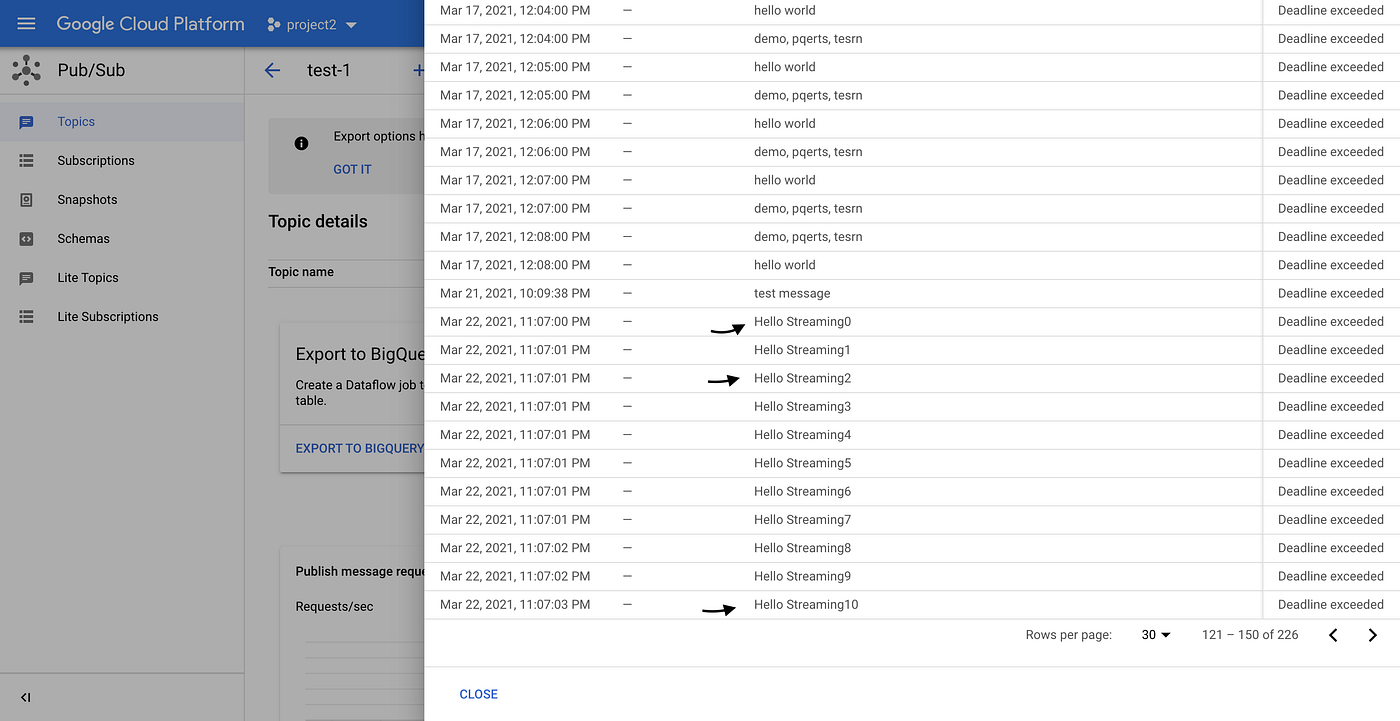
- Now we verified that data is indeed published in Cloud Pubsub.Let process the read and process the record using cloud dataflow in the Step 3.
Data Processing
- Cloud Dataflow is unified distributed processing engine which uses apache beam sdk to build the data pipeline(batch & realtime).
- In this example we will build realtime pipeline.
- Goal is to read the published message from PubSub , validate the record and filter “Hello Streaming” and Interger ex. “1” and finally write to bigquery in the target table.


- Now we can execute above dataflow pipeline using maven command
/* export service account prior to run below command to provide access to various services
export GOOGLE_APPLICATIONS_CREDENTIALS=~/service_account.json
*/$mvn -Pdataflow-runner compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.PubsubToBQ \
-Dexec.args="--project=$PROJECT_ID \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_NAME \
--stagingLocation=$CLOUD_STPRAGE_BUCKET \
--tempLocation=$CLOUD_STPRAGE_BUCKET/temp \
--runner=DataflowRunner \
--region=us-central1"
- After executing this command lets check Dataflow console for visualization of our pipeline
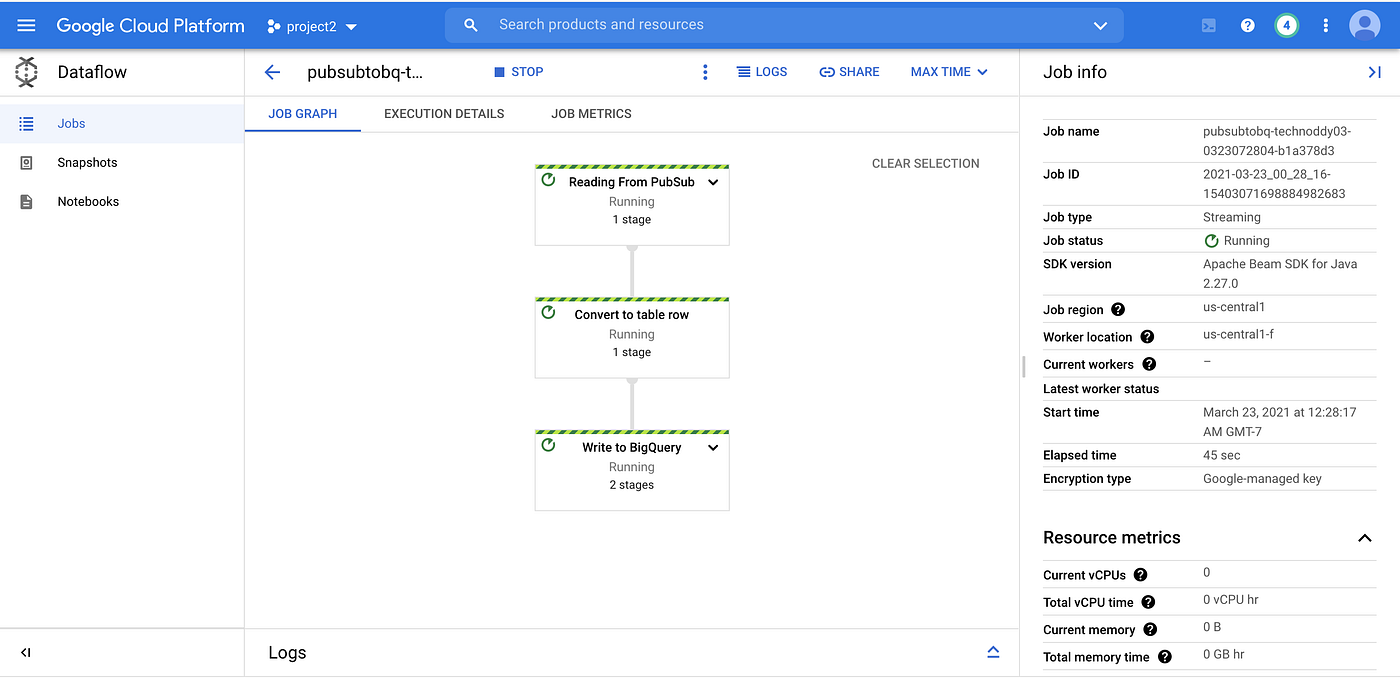
- Now lets generate some messages from pubsub client that we build in Step 1
- All the successfull message should be able to process via data flow streaming job. if you click “Reading From PubSub” step in the DAG, you can see it read 218 elements so far.
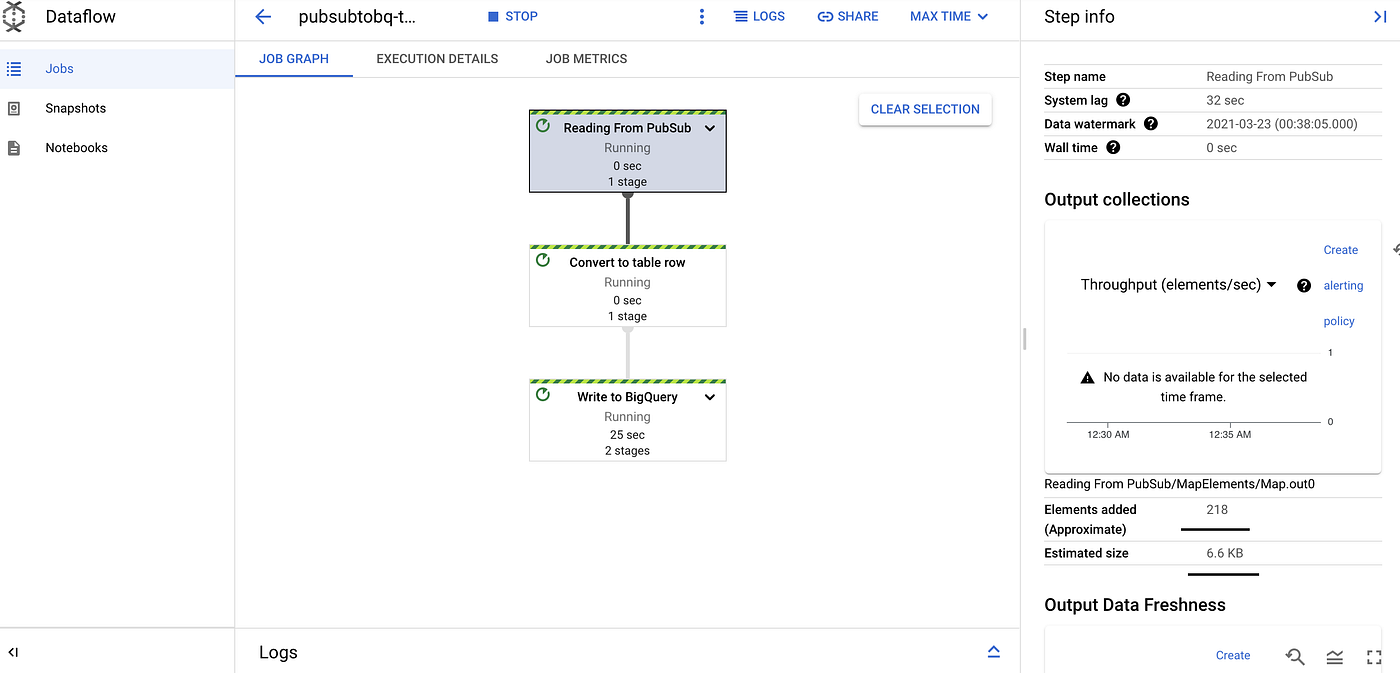
- Now lets move to next step to verify if dataflow process the data and wrote it to BigQuery Successfully.
Data Sink
- Goto BigQuery by clicking on Hamburger menu in google cloud console and Clicking BigQuery in the left menu bar.
- If we navigate to our target table hello_string , we will see indeed string buffer statistics shows 218 elements were streamed to BigQuery, which verifies that all the element published to pubsub were written successfully to BigQuery.
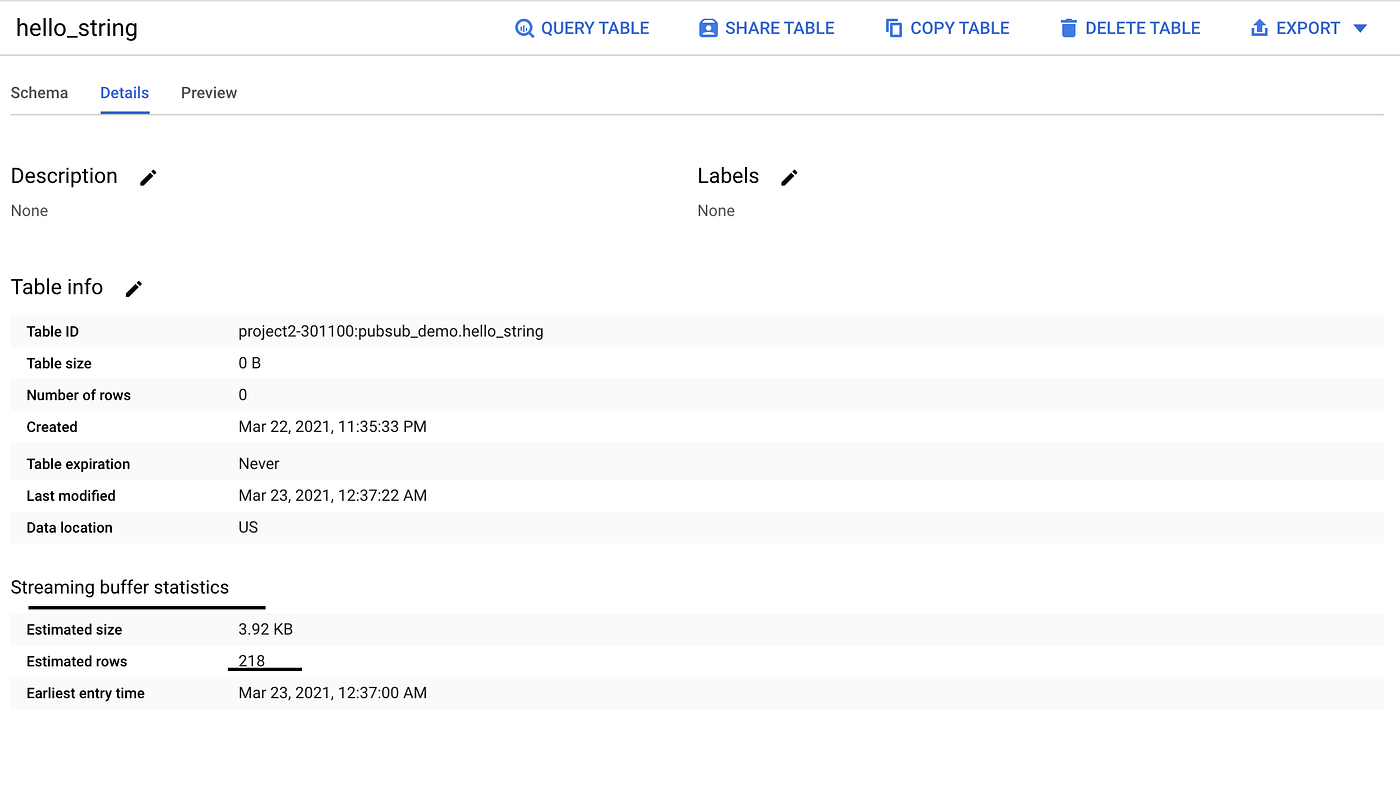
- Now lets dive into table to see the data .
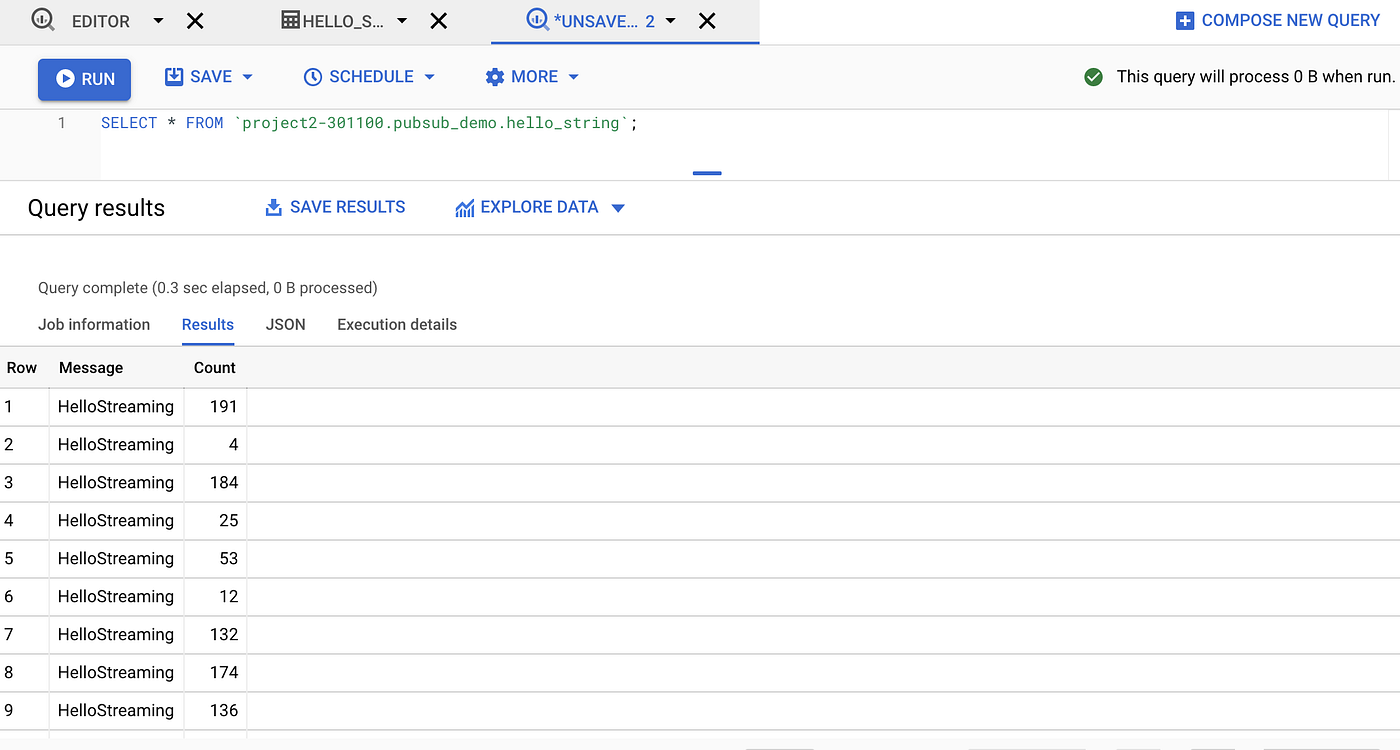
- Indeed data has been written successfully into BigQuery. You can also verify the max count to be 217 ( since message count was 0 index) by running below query
SELECT max(Count) FROM `$PROJECT_ID.$TABLE_NAME.hello_string`;
Conclusion
- Writing Realtime streaming pipeline is not difficult in GCP. One can easily get started building POCs without handling installation since all the services we used in the demo are serverless.
- I highly recommend to play and build complex use cases and see how much time it really takes to desingn and develop your pipeline.
- Do comment your experiance. We always learn from each other.