
Understanding Scalar Projection in Spring Data JPA
Introduction
- Query projection is one of the most important things when we write a query in JPA since it determines which column we are selecting from the table and how to map that to the appropriate data type in Java (i.e. dto, entity, object[], tuple, etc.)
- In this article we will learn about one such projection type called scalar projection and when to use it.
Scalar Projection
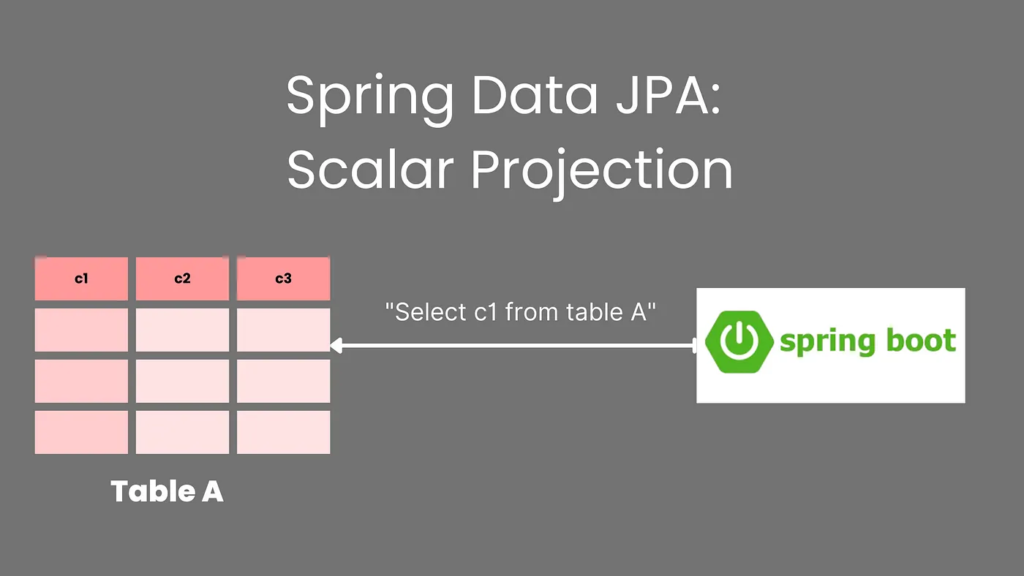
- In JPA we query the database and return an entity as a result that represents a row or list of rows in the database.
- But we do not need all the fields in the entity always and need only a few attributes or we have a custom query that doesn’t have an entity mapped to it.
- In such cases, it’s helpful to use a scalar projection that allows us to use return objects using index or parameter names and operate on them.
Use Case
- Consider an Account Table in the database that has the below fields
@Entity
@Table(name="ACCOUNTS")
public class Account {
@Id @GeneratedValue(strategy= GenerationType.SEQUENCE, generator = "accounts_seq")
@SequenceGenerator(name = "accounts_seq", sequenceName = "accounts_seq", allocationSize = 1)
@Column(name = "user_id")
private int userId;
private String username;
private String password;
private String email;
private Timestamp createdOn;
private Timestamp lastLogin;
// getters , setters
}
- Let’s say that we query for all the users with attributes username and password using the createQuery method on entitymanager instance.
SELECT a.username, a.password from Account a
- Now we cannot map the result of this query to the Account entity, if we do we will have a mapping error. And for custom queries where we perform many joins and refer different columns, we will not always have an entity handy for the result.
- In such cases, we can use Object[] array as the return type and access them using the index as shown below.
TypedQuery<Object[]> query = em.createQuery("SELECT a.username, a.password from Account a", Object[].class);
List<Object[]> accounts = query.getResultList();
accounts.forEach(a->System.out.println(a[0]+","+a[1]));
- We can also use Tupe type as return data type, which also allows us to access return columns with index.
TypedQuery<Tuple> query1 = em.createQuery("SELECT a.username as username, a.password as password from Account a", Tuple.class);
List<Tuple> accounts1 = query1.getResultList();
accounts1.forEach(a-> System.out.println(a.get(0)+", "+a.get(1)));
- The best part is that we can also access the column by their name instead of the index which makes code more readable, but make sure to have an alias for the columns by which we will refer them in tuple.
TypedQuery<Tuple> query1 = em.createQuery("SELECT a.username as username, a.password as password from Account a", Tuple.class);
List<Tuple> accounts1 = query1.getResultList();
accounts1.forEach(a-> System.out.println(a.get("username")+", "+a.get("password")));
Conclusion
- In this short article, we will learn a very useful feature of JPA called Scalar projection which is very useful when we don’t have an entity or dto handy to map the result of the query.
Before You Leave
- Upgrade your Java skills with Grokking the Java Interview
- If you want to upskill your Java skills, you should definitely check out
[NEW] Master Spring Boot 3 & Spring Framework 6 with Java
[ 38 hrs content, 4.7/5 stars, 6+ students already enrolled]